|
xcampus.jp
|
XCAMPUSトップ(ログイン) | XCAMPUS一般事例 | XCAMPUS xbrl | XCAMPUS構文解説 |
|
xcampus.jp
|
XCAMPUSトップ(ログイン) | XCAMPUS一般事例 | XCAMPUS xbrl | XCAMPUS構文解説 |
第 20 章
ユーザデータセクション($$u):横断面($c)・入力変量リスト($l)
書式($c in $$u)例1
書式($c in $$u)例1の出力結果
書式($c in $$u)例2
書式($c in $$u)例2の出力結果
書式($c in $$u)例3
書式($c in $$u)例4
書式($c in $$u)例4の出力結果
書式($c in $$u)例5
書式($c in $$u)例5の出力結果
この章では,主としてクロスセクションのユーザ・データを入力するためのコマンドやパラメータを説明する.なお,ユーザ・データ・セクションは,前章で述べているように「$$u」で開始され,時系列のユーザ・データの入力については前章を参照されたい.
本ページの書式例参照プログラムはWeb版xcampusの場合は各大学のWeb版のプログラム事例として収録され,クリック1つですぐに実行できる.Windows版の場合は,xcampusの[ファイル]メニューの[開く]をクリックして,xcampusの見本プログラム群の[rffmtprg]フォルダに収録されている.Linux版xcampusの場合は,コマンド xccp を入力することによってプログラム一覧が表示される.なお,ユーザファイルを用いるプログラムはWeb版xcampusでは取り扱わない.
クロスセクション・ユーザデータの属性指示コマンドは,次の形式をとる.
| $c |
クロスセクション・ユーザデータの属性指示パラメータは,上述の「$c」コマンドに続いて,次の2タイプのいずれかの形式で記述する.
書式($c in $$u)例1
書式($c in $$u)例1の出力結果
書式($c in $$u)例2
書式($c in $$u)例2の出力結果
書式($c in $$u)例3
書式($c in $$u)例4
書式($c in $$u)例4の出力結果
書式($c in $$u)例5
書式($c in $$u)例5の出力結果
$$u
$d
reset
1゜ 2゜ 3゜ 4゜
| ◎◎◎◎,◎◎◎◎,変量名;単位 |
1゜ 3゜ 4゜
| △△△△△△△△△,変量名;単位 |
<ユーザデータ・
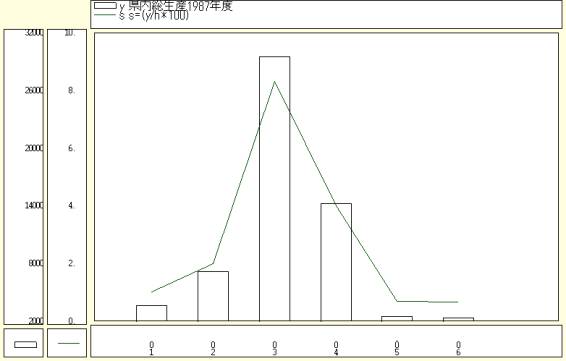
マクロ:近畿各府県の県内総生産の国内総生産に占めるシェア(1987年度)> ユーザデータとして近畿の各府県の県名と1987年度県内総生産を入力する書式例である.| ============== u-c-f1.txt ========= ====================== ユーザデータセクション $$u $c //クロスセクション属性指示コマンド 0001,0006,:n1,県名 //(最初の漢字県名2文字) △△△△△△△△△,:n2,県名 //(次の漢字県名2文字) (△はスペース1文字) △△△△△△△△△,県内総生産1987年度 //(△はスペース1文字) -------------------- $d //データ内容コマンド ctype //データ内容パラメータ<ケースごと記述タイプ> 滋賀,県,3666 //滋賀県の文字,数値 京都,府,7174 //京都府 大阪,府,29556 //大阪府 兵庫,県,14239 //兵庫県 奈良,県,2506 //奈良県 和歌,山県,2406 //和歌山県 ======================== 日本経済セクション $$n --------------- time series $t //時系列入力コマンド GDPBY90,国内総生産 //国内総生産(名目) 旧68SNA・1990年基準計数(MTコード11000007) --------------- list $l //入力変量リストコマンド ========================= 変量分析セクション $$v $a //変量記号割当コマンド x,国内総生産 N,:n1,県名 //(最初の漢字県名2文字) M,:n2,県名 //(次の漢字県名2文字) y,県内総生産1987年度 ------------------- $d //表示範囲コマンド all //全範囲 --------------- transform $t //変数変換コマンド x=&.s(x)1,2 //[&.s]データ編集(国内総生産)[1,2]-->年度へ,第2四半期始点 h=@."(x)1987.0 //時系列の1時点(1987年)のスカラー変量作成 s=(y/h*100) //県内総生産の国内総生産に占めるシェア P=:ci(y) //ケース(府県)識別文字列 △=pr*(N,M,y,s,P) //数値プリント(県別) (△はスペース1文字) △=pr*(h) //数値プリント(国内総生産1987年度) (△はスペース1文字) ======================== グラフセクション $$g $d //表示範囲コマンド all //全範囲 ---------------- $p //プロットコマンド y,s //県内総生産(y),シェア(s) ======================= 終了セクション $$ |
書式($c in $$u)例1のプログラム参照[u-c-f1.txt]
<ユーザデータ・
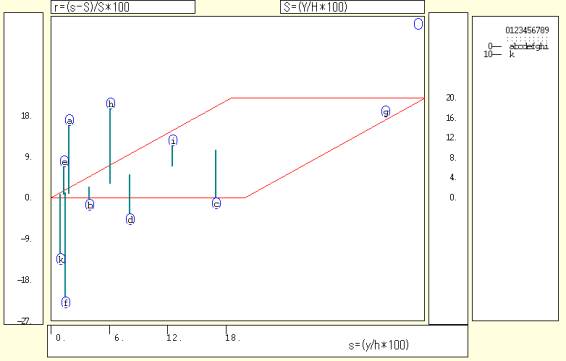
マクロ:県内総生産の1987年度の各県シェア,1972年度シェア,| =========== u-c-f2.txt ========= ====================== ユーザデータセクション $$u $c //クロスセクション属性指示コマンド 0001,0011,:n1,県名 //(最初の漢字県名2文字) △△△△△△△△△,:n2,県名 //(次の漢字県名2文字)(△はスペース1文字) △△△△△△△△△,県内総生産1987年度 // (△はスペース1文字) △△△△△△△△△,県内総生産1972年度 // (△はスペース1文字) -------------------- $d //データ内容コマンド ctype //データ内容パラメータ<ケースごと記述タイプ> 滋賀,県,3666,858 //滋賀県の文字,数値 京都,府,7174,2027 //京都府 大阪,府,29556,9069 //大阪府 兵庫,県,14239,4279 //兵庫県 奈良,県,2506,635 //奈良県 和歌,山県,2406,859 //和歌山県 東京,都,63316,17329 //東京都 千葉,県,12066,2792 //千葉県 愛知,県,23707,6096 //愛知県 広島,県,8127,#N/A //広島県 高知,県,1718,543 //高知県 ======================== 日本経済セクション $$n --------------- time series $t //時系列入力コマンド GDPBY90,国内総生産 //国内総生産(名目) 旧68SNA・1990年基準計数(MTコード11000007) --------------- list $l //入力変量リストコマンド ========================= 変量分析セクション $$v $a //変量記号割当コマンド x,国内総生産 N,:n1,県名 //(最初の漢字県名2文字) M,:n2,県名 //(次の漢字県名2文字) y,県内総生産1987年度 Y,県内総生産1972年度 ------------------- $d //表示範囲コマンド all //全範囲 --------------- transform $t //変数変換コマンド x=&.s(x)1,2 //[&.s]データ編集(国内総生産)[1,2]-->年度へ,第2四半期始点 h=@."(x)1987.0 //時系列の1時点(1987年)のスカラー変量作成 H=@."(x)1972.0 //時系列の1時点(1972年)のスカラー変量作成 s=(y/h*100) //県内総生産の国内総生産に占めるシェア1987年度クロスセクション S=(Y/H*100) //県内総生産の国内総生産に占めるシェア1972年度クロスセクション r=(s-S)/S*100 //シェアの変動率クロスセクション P=:ci(y) //ケース(府県)識別文字列 △=pr*(N,M,y,s,Y,S,r,P) //数値プリント(県別)(△はスペース1文字) △=pr*(h,H) //数値プリント(国内総生産1987年度,1972年度)(△はスペース1文字) ======================== グラフセクション $$g $d //表示範囲コマンド all //全範囲 ---------------- $p //プロットコマンド yY //県内総生産1987年度(y),1972年度(Y) sS //シェアクロスセクション1987年度(s),1972年度(S) r //シェアの変動率クロスセクション ------------------ $c //散布図 s,S,*,P //シェア1987年度(s),シェア1972年度(S),回帰線(*),ケース識別文字(P) ------------------ $3 //3次元図 r,s,S,P //シェアの変動率(r),シェア1987年度(s),シェア1972年度(S),ケース識別文字(P) ======================= 終了セクション $$ |
書式($c in $$u)例2のプログラム参照[u-c-f2.txt]
前書式($c in $$u)例2と同じ内容のプログラムである.異なるのは,データ内容($d)コマンドの部分で,cfileのパラメータを指示して,外部のユーザファイルからデータコンテンツを読み込む点である.
| ========== u-c-f3.txt ========= ====================== ユーザデータセクション $$u $c //クロスセクション属性指示コマンド 0001,0011,:n1,県名 //(最初の漢字県名2文字) △△△△△△△△△,:n2,県名 //(次の漢字県名2文字)(△はスペース1文字) △△△△△△△△△,県内総生産1987年度 // (△はスペース1文字) △△△△△△△△△,県内総生産1972年度 // (△はスペース1文字) -------------------- $d //データ内容コマンド ユーザファイル u-c-f3uf.txt cfile //データ内容パラメータ<ケースごと記述のユーザファイル読み込みタイプ> |
外部のユーザファイルには,各都府県の県名先頭漢字2文字,次の漢字2文字,1987年度の県内総生産の数値,1972年度の県内総生産の数値を各1行に記述し,欠落値は「#N/A」で記述している.//はコメント文である.Excelの表計算シートに記述し,テキストファイルとして保存したものでも構わない.
なおこの書式例をWindows版xcampusで実行するには,メニュー[XC実行]で[入力ファイルを伴なう処理]を選び,コンテンツの所在するファイルを指示する.Web版xcampusではユーザファイルを取り扱わないのでこの書式例の実行はできない.Linux版xcampusでは -in オプションをつけて xcrun
を実行し,プロンプトに対してユーザファイルを指示する.
// 書式($c in $$u)例3 u-c-f3.txt で読み込むユーザファイル
滋賀,県,3666,858 //滋賀県の文字,数値
京都,府,7174,2027 //京都府
大阪,府,29556,9069 //大阪府
兵庫,県,14239,4279 //兵庫県
奈良,県,2506,635 //奈良県
和歌,山県,2406,859 //和歌山県
東京,都,63316,17329 //東京都
千葉,県,12066,2792 //千葉県
愛知,県,23707,6096 //愛知県
広島,県,8127,#N/A //広島県
高知,県,1718,543 //高知県
書式($c in $$u)例3のプログラム参照[u-c-f3.txt]
書式($c in $$u)例3のユーザファイル参照[u-c-f3uf.txt]
<ユーザデータ・
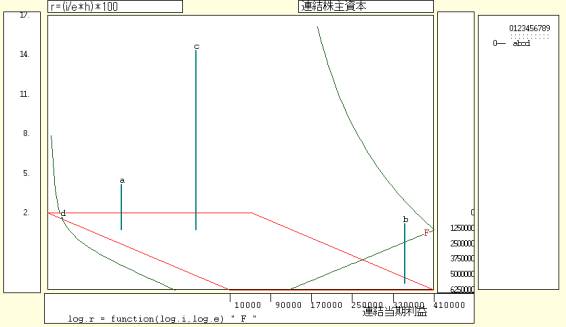
連結決算:自動車メーカーの1996年度の連結売上高,連結ROE,世界生産台数> 連結財務データにユーザが入手したデータを組み合わせる例題である.日本の自動車メーカーの連結決算データに世界生産台数を加えて分析を試みている.| ============= u-c-f4 ====================== $$c //連結財務データセクション $f //処理対象企業フラグコマンド <g>==..(7004)1351,1353,1392,18962 //★日産,トヨタ,本田,三菱の日経会社コード順に指示 $n //企業名コマンド lst,<g> //フラグgの企業のリスト出力 :n1,<g> //企業名の最初の漢字2文字 :n2,<g> // 次の漢字2文字 :n3,<g> // その次の漢字2文字 $p //原数値プリントコマンド .... 【新項番3001】 売上高・営業収益 .... 【新項番3006】 営業利益 .... 【新項番3008】 受取利息・割引料・有価証券利息 .... 【新項番3009】 受取配当金 .... 【新項番3016】 支払利息・割引料 .... 【新項番3058】 当期利益 .... 【新項番5056】 従業員数(単位:人) .... 【新項番1026】 連結子会社数(単位:社) <g>,3001,3006,3008,3009,3016,3058,5056,1026 //項番指示(最初の30社までプリント) $r //期間限定コマンド 新期間指定(西暦年4桁表記) 1996.04,1997.03 //★1996年4月から1997年3月までの1996年度に限定 $c //クロスセクションコマンド flw,3001,<g>,連結売上高 flw,3006,<g>,連結営業利益 flw,3058,<g>,連結当期利益 stk,2125,<g>,連結株主資本 ========================== $$u //ユーザデータセクション $c //クロスセクション属性指示コマンド 0001,0004,生産台数;万台 //★ケース範囲,変量名;単位 $d //ユーザデータ内容入力コマンド ctype //データ内容パラメータ<ケースごと記述タイプ> 274 //★日産 世界生産台数1996年度実績 488 //★トヨタ 出所:日本経済新聞1998.5.8 216 //★本田 198 //★三菱 $l //入力変量名リスト ============================ $$v //変量分析セクション $a //変量記号割当コマンド N,:n1,<g> //最初の企業名漢字2文字 A,:n2,<g> //次の企業名漢字2文字 M,:n3,<g> //その次の企業名漢字2文字 s,連結売上高 p,連結営業利益 i,連結当期利益 e,連結株主資本 c,生産台数 $t //変数変換コマンド △=pr*(N,A,M,s,p,i,e,c) //数値プリント(△は半角スペース) h=f>=(e)100 //株主資本が100百万円以上のフラグh r=(i/e*h)*100 //以上の条件hを満たすケースの連結ROE F=(1,-1,log100) //関数ベクトルF P=:ci(s) //ケース識別文字系列 △=pr*(N,A,M,r,P) //数値プリント(△は半角スペース) ============================= $$g //グラフセクション $p //プロットコマンド r,c,s //連結ROE(r),生産台数(c),連結売上高(s) $c //散布図コマンド r,c,*,P //連結ROE(r),生産台数(c),回帰線(*),ケース識別文字(P) $3 //3次元図コマンド r*i*e*P,F //縦軸r(対数*),横軸i(対数*),奥行軸e(対数*),印字(P),関数表示(F) ======================= 終了セクション $$ |
書式($c in $$u)例4の旧プログラム・テキスト参照[u-c-f4-old.txt]
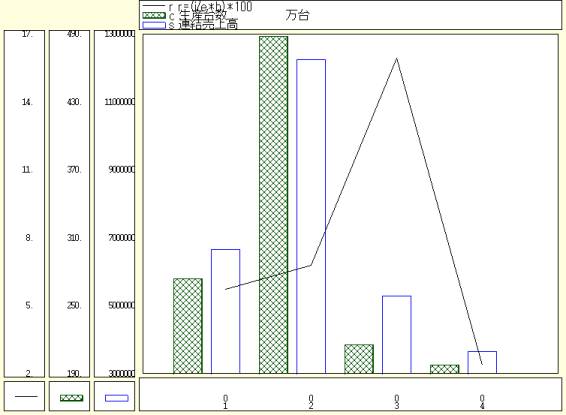
自動車メーカーの1996年度の連結ROE,世界生産台数,連結売上高のプロット![]()
自動車生産メーカー4社,つまり日産自動車(ケース番号1),トヨタ自動車(ケース番号2),本田技研工業(ケース番号3),三菱自動車工業(ケース番号4)の連結ベースの計数と生産台数をプロットしている.規模ではトヨタが大きく,株主資本利益率ROEでは本田技研が高い.
<ユーザデータ・
単独決算:石油元売り各社の1996年度の単独決算ROEとガソリンスタンド数の散布図>ビジネス財務データにユーザが入手したデータを組み合わせる例題である.日本の石油元売り各社の単独決算データにガソリンスタンド数を加えて分析を行っている.
ビジネス財務($$b)セクションにおいて,まずフラッグ作成($f)コマンドで石油元売り各社にフラッグgを立てる.日経会社コード(項番7004,単独旧項番455)のコード順に指示する.企業名($n)コマンドで,漢字企業名を2文字ずつ3変量に分けて作成する.原数値($p)コマンドで,単独決算の売上高(項番3001,旧項番090),営業利益(項番3006,旧項番095)等々の素データを出力する.次に期間限定($r)コマンドで,1996年度を指示し,クロスセクション($c)コマンドで,フラグgの立っている企業の売上高,営業利益,当期利益(項番3058,旧項番128),株主資本(資本合計,項番2125,旧項番078)のクロスセクション系列を作成する.
ユーザ($$u)セクションにおいてクロスセクション属性指示($c)コマンドで,入力ケース範囲と変量名を指示している.クロスセクション属性指示パラメータで,石油元売り6社のケース範囲を「0001,0006」と指示し,変量名として「スタンド数」と記述している.
次にデータ内容($d)コマンドで,ケースごと記述の(ctype)パラメータの直後に,各社別にガソリンスタンド数の1997年3月末の店数を1行ずつ記述している.記述の仕方については,前章のユーザデータ内容コンテンツの項を参照されたい.「//」以降の文字はコメント文である.次に入力変量名リスト($l)コマンドで,財務データの入力変量を含む全入力変量の一覧を出力している.
変量分析セクション($$v)で,以上で入力した諸変量に英字1文字の変量記号を割り当て,1996年度の株主資本利益率(ROE)とガソリンスタンド数の関係などを調べている.
この書式例のガソリンスタンド数の代わりに株価などで分析することもできよう.
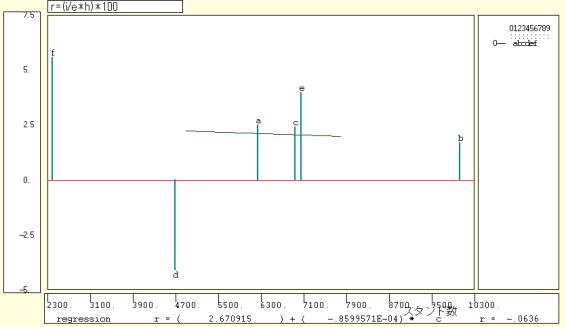
| ============= u-c-f5 =================================== $$b //ビジネス財務データセクション $f //処理対象企業フラグコマンド ...................... Jエナジー,日石,昭和シェル,三菱石,コスモ,ゼネラル石の <g>==..(7004)48,661,662,664,667,1615 //★各社を日経会社コード順に指示 $n //企業名コマンド lst,<g> //フラグgの企業のリスト出力 :n1,<g> //企業名の最初の漢字2文字 :n2,<g> // 次の漢字2文字 :n3,<g> // その次の漢字2文字 $p //原数値プリントコマンド .... 【新項番3001】 売上高・営業収益 .... 【新項番3006】 営業利益 .... 【新項番3008】 受取利息・割引料・有価証券利息 .... 【新項番3009】 受取配当金 .... 【新項番3016】 支払利息・割引料 .... 【新項番3058】 当期利益 .... 【新項番5056】 従業員数(単位:人) <g>,3001,3006,3008,3009,3016,3058,5056 //項番指示(最初の30社までプリント) $r //期間限定コマンド 新期間指定(西暦年4桁表記) 1996.04,1997.03 //★1996年4月から1997年3月までの1996年度に限定 $c //クロスセクションコマンド flw,3001,<g>,売上高 flw,3006,<g>,営業利益 flw,3058,<g>,当期利益 stk,2125,<g>,株主資本 ========================== $$u //ユーザデータセクション $c //クロスセクション属性指示コマンド 0001,0006,スタンド数 //★ケース範囲,変量名;単位 $d //ユーザデータ内容入力コマンド ctype //データ内容パラメータ<ケースごと記述タイプ> 6232 //★Jエナジー ガソリンスタンド数1997年3月末 10018 //★日石 出所:日本経済新聞1998.6.3 6937 //★昭和シェル 4680 //★三菱石 7048 //★コスモ 2382 //★ゼネラル石 $l //入力変量リスト ============================ $$v //変量分析セクション $a //変量記号割当コマンド N,:n1,<g> //最初の企業名漢字2文字 A,:n2,<g> //次の企業名漢字2文字 M,:n3,<g> //その次の企業名漢字2文字 s,売上高 p,営業利益 i,当期利益 e,株主資本 c,スタンド数 $t //変数変換コマンド △=pr*(N,A,M,s,p,i,e,c) //数値プリント(△は半角スペース) h=f>=(e)100 //株主資本が100百万円以上のフラグh r=(i/e*h)*100 //以上の条件hを満たすケースのROE F=(1,-1,log100) //関数ベクトルF P=:ci(s) //ケース識別文字系列 △=pr*(N,A,M,r,P) //数値プリント(△は半角スペース) ============================= $$g //グラフセクション $p //プロットコマンド r,c,s //ROE(r),スタンド数(c),売上高(s) $c //散布図コマンド r,c,*,P //ROE(r),スタンド数(c),回帰線(*),ケース識別文字(P) $3 //3次元図コマンド r*i*e*P,F,* //縦軸r(対数*),横軸i(対数*),奥行軸e(対数*),印字(P),重合せ保存(*) r,i,e,P,* //縦軸r,横軸i,奥行軸e,印字(P),重ね合せ保存(*) △△△△△△△△ //重ね合せ図 ======================= 終了セクション $$ |
書式($c in $$u)例5の旧プログラム・テキスト参照[u-c-f5-old.txt]
他のセクションの入力変量も含めて,これまでに入力された全変量名のリストを,[数値リスト]に出力する.1種類のコマンドのみでパラメータは不要である.
入力変量リスト(list)コマンドは次の形式をとる.
| $l |
パラメータなし
ユーザのクロスセクション・データを入力する書式($c in $$u)例5 のユーザ($$u)セクション部分の再掲である.リスト出力部分($l)は最後の行のようになる.出力結果は,ビジネス財務($$b)セクションのリスト出力($l)と同様であるので,第5章の書式($c in $$b)例2の入力変量リスト をみられたい.
| ============= u-c-f5 =================================== [省略] ========================== $$u //ユーザデータセクション $c //クロスセクション属性指示コマンド 0001,0006,スタンド数 //ケース範囲,変量名;単位 $d //ユーザデータ内容入力コマンド ctype //データ内容パラメータ<ケースごと記述タイプ> 6232 //Jエナジー ガソリンスタンド数1997年3月末 10018 //日石 出所:日本経済新聞1998.6.3 6937 //昭和シェル 4680 //三菱石 7048 //コスモ 2382 //ゼネラル石 $l //入力変量名リストコマンド |
![]()
![]()
![]()
![]()
![]()